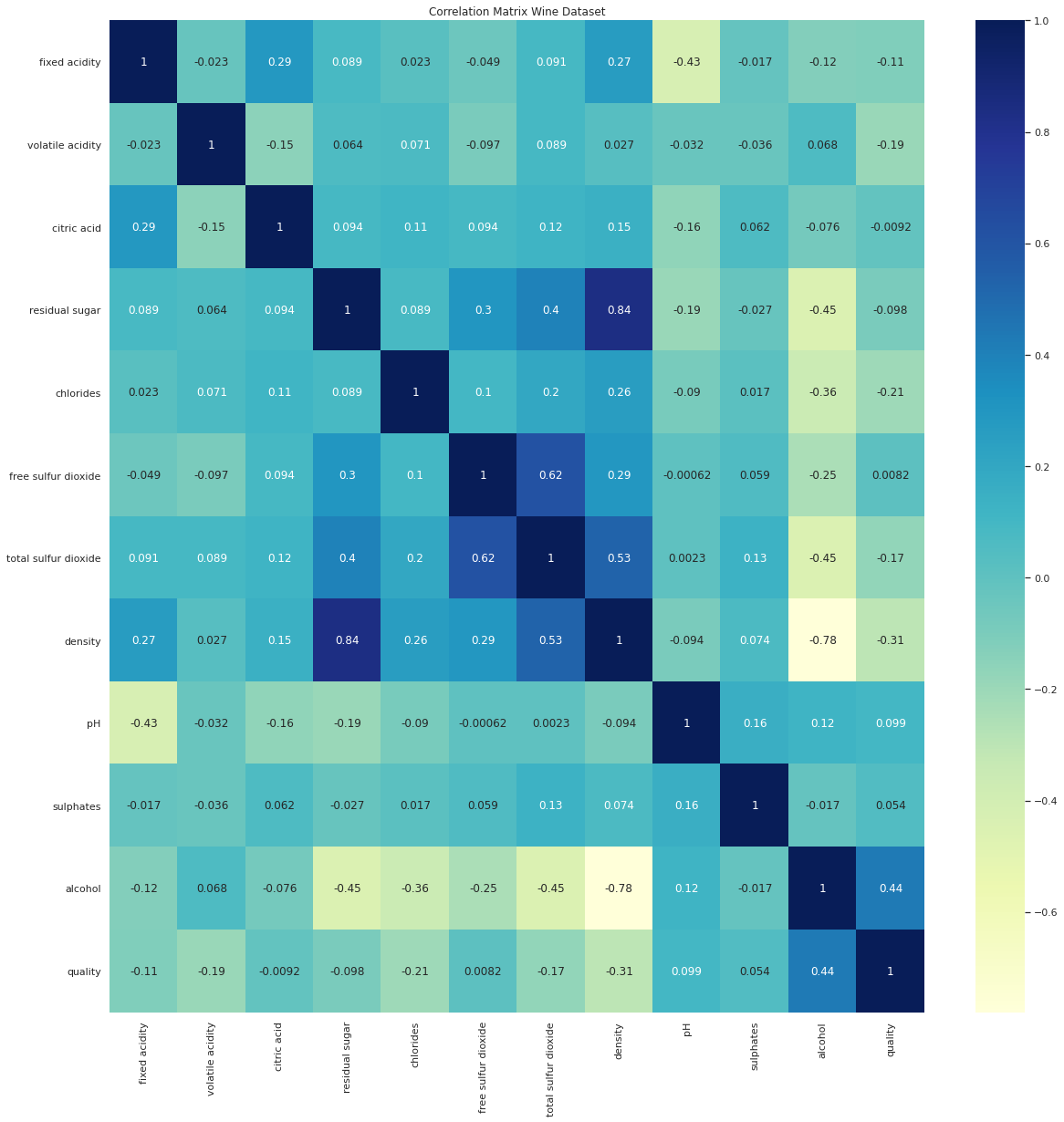
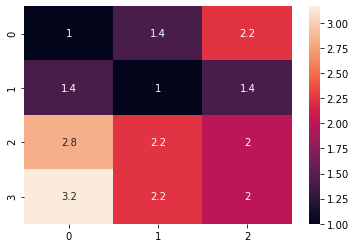
In response to the growing usage of our windows application and the need to enhance its performance, our development team embarked on a project to refactor our legacy C# codebase. A key focus of this effort was to streamline the application’s memory usage to ensure optimal performance and scalability. Recognizing that inefficient memory management can […]
Ram and CPU usage optimization in C# code