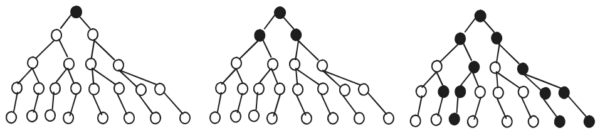
Beam search is a heuristic search algorithm, a variant of breadth first search designed in such a way that it only explores a limited set of promising paths or solutions in a search space instead of all possible paths, which is often computationally expensive. It is used in the field of artificial intelligence, particularly in the context of search and optimization problems. The main difference between BEAM search and breadth-first search is that at every level of the search tree, only the top \(\beta\) candidates are chosen for further exploration. Here, \(\beta\) is known as the beam width. The reasoning behind this is that a path from source to destination is likely to pass through some top number of most promising nodes. This leads to an algorithm that is fast and memory-efficient because it can disregard many nodes that may appear to be too far from the goal. An evaluation function is used to evaluate the candidacy of nodes for further exploration.
Here is an analogy that may help you better understand beam search:
Imagine trying to find the shortest path from your house to a grocery store. You start by walking in the direction you think will lead you there, keeping track of different paths as you walk. At each intersection, you consider the available options and choose the one most likely to lead you to the store. Beam search is a search algorithm that works similarly. It only keeps track of a limited number of paths at each iteration.
If the beam width is too small, the algorithm may not find the best path. Conversely, if the beam width is too large, the algorithm may use too much memory. This renders the algorithm incomplete, meaning that finding the shortest path is not guaranteed. Beam search is suitable for problems where an exact solution is not required, and a good approximation is sufficient.
The trade-off between beam width and solution quality is crucial in beam search. A narrower beam focuses on the best candidates but may miss global optima. A wider beam explores a larger portion of the search space but may spend more time on unpromising paths. The choice of beam width depends on the specific problem and the desired trade-off between speed and solution quality.
How it works
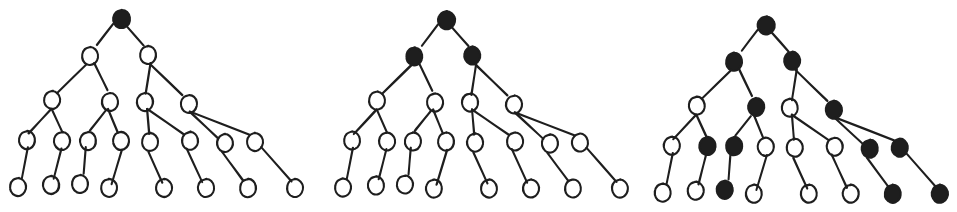
Beam search uses an open set prioritized based on the total cost and a closed set to keep track of visited nodes. The algorithm begins with a start node S, which also serves as the root node for the search tree.
- Initialize a search tree with the root node being the start node S.
- Add S to the closed set and evaluate all successors of node S.
- Select the top $latex \beta$ (beam width) nodes and add them as children to S in the tree. Ignore all other nodes.
- Add the selected nodes to the open set for further exploration.
- Remove all nodes in the open set. Once a node is removed for exploration, add it to the closed set.
- Evaluate all adjacent nodes and sort them according to the evaluation function.
- Select the top $latex \beta$ nodes and add them to the tree, adding them as children of their respective parent nodes.
- Repeat this process until the goal node G is found in the open set, indicating that a path has been found.
Implementation
Below is a Python program that demonstrates the Beam Search algorithm to find the shortest path in a weighted graph from a start node to a goal node with a specified beam width.
import queue
def beam_search(graph, start, goal, beam_width):
open_set = queue.PriorityQueue()
open_set.put((0, start))
closed_set = set()
# A dictionary to represent the search tree
search_tree = {start: None}
while not open_set.empty():
print(open_set.queue, closed_set)
current_cost, current_node = open_set.get()
if current_node == goal:
# Goal reached, reconstruct and return the path
path = []
while current_node is not None:
path.insert(0, current_node)
current_node = search_tree[current_node]
return path
closed_set.add(current_node)
successors = graph[current_node]
successors.sort(key=lambda x: x[1]) # Sort successors by cost
for successor, cost in successors[:beam_width]:
if successor not in closed_set:
open_set.put((current_cost + cost, successor))
search_tree[successor] = current_node
# If goal not reached
return None
# Example graph represented as an adjacency list with costs
graph = {
'A': [('E', 4), ('C', 2), ('I', 4)],
'B': [],
'C': [('F', 1), ('G', 2), ('H', 8)],
'D': [('B', 2)],
'E': [('F', 2), ('C', 2), ('H', 5)],
'F': [('H', 4), ('G', 1)],
'G': [('D', 3)],
'H': [('B', 6)],
'I': [('H', 3)]
}
start_node = 'A'
goal_node = 'B'
beam_width = 2 # Adjust the beam width as needed
path = beam_search(graph, start_node, goal_node, beam_width)
if path:
print("Shortest Path:", ' -> '.join(path))
else:
print("No path found.")
Time Complexity Analysis
The time complexity of Beam Search depends on several factors, including the size of the search space, the characteristics of the problem, and the chosen beam width. Let’s break down the time complexity analysis:
-
Search Space Size \(N\):
- Beam Search explores a limited set of candidates at each level, controlled by the beam width \(\beta\). The number of nodes at each level that need to be considered is \(O(\beta)\).
-
Depth of the Search Tree \(D*\):
- The depth of the search tree depends on the distance from the start node to the goal node. Let’s denote the depth of the optimal solution as \(O( \beta^D*)\).
-
Overall Time Complexity:
- The overall time complexity of Beam Search is approximately \(O( \beta^D*)\).
-
Comparison with Other Algorithms:
- Compared to uninformed search algorithms like breadth-first search, which has a time complexity of \(O(b^D)\), where \(b\) is the branching factor, Beam Search can be more efficient when \(\beta\) << \(b\). However, it may be less efficient when \(\beta\) approaches or exceeds \(b\).
-
Influence of Heuristic Evaluation:
- If a heuristic function is used to guide the search, the time complexity is influenced by the efficiency and accuracy of the heuristic. A more effective heuristic can significantly reduce the number of nodes explored.
-
Best, Worst, and Average Case:
- The best-case scenario occurs when the goal is found early in the search, leading to a time complexity close to \(O( \beta)\). The worst-case occurs when the goal is at the maximum possible depth, resulting in a time complexity of \(O( \beta^D)\). The average-case time complexity is challenging to determine precisely and depends on the characteristics of the problem.
-
Time Complexity in Practice:
- In practice, the efficiency of Beam Search often depends on the ability to find good solutions quickly with a limited beam width. The algorithm’s performance can be sensitive to the choice of the beam width and the characteristics of the problem.
Advantages
- Efficient: Beam search is a very efficient search algorithm, especially for large and complex problems. This is because beam search only explores a limited number of paths at each iteration.
- Flexible: Beam search can be used to find a variety of different types of solutions, including optimal solutions, suboptimal solutions, and constrained solutions.
Limitations
- Incompleteness: Beam search is not a complete search algorithm, which means that it may not always find a solution to a problem, even if a solution exists. This is because beam search only explores a limited number of paths at each iteration.
- Sensitivity to beam width: The performance of beam search is sensitive to the choice of beam width. A too small beam width may cause the algorithm to miss the optimal solution, while a too large beam width may make the algorithm inefficient.
Applications
Beam search is a powerful algorithm with a wide range of applications across various domains. Here are some of the most common applications:
Natural language processing (NLP):
- Machine Translation: Beam search is widely used in machine translation to decode the output sequence word by word. It allows the model to explore different translation options and choose the most likely one based on the context and the overall translation quality.
- Text Summarization: Beam search can be used to summarize text by generating a shorter version that captures the main points of the original text. The algorithm can be used to find the most concise and informative summary that retains the key ideas.
- Dialogue Systems: Beam search is employed in dialogue systems to generate responses that are relevant to the conversation history and user intent. It allows the system to explore different response options and choose the one that best fits the context and user expectations.
Computer Vision:
- Image Captioning: Beam search can be used to generate captions for images. It allows the model to consider different interpretations of the image and generate captions that are relevant and descriptive.
- Object Detection and Recognition: Beam search can be used to detect and recognize objects in images. It helps the model identify multiple objects and their positions within the image by exploring different potential detections and selecting the most likely ones.
- Video Captioning: Beam search can be used to generate captions for videos by analyzing the video content and generating summaries that capture the key events and actions.
Speech Recognition:
- Automatic Speech Recognition (ASR): Beam search is applied in ASR systems to translate speech signals into text. It allows the system to consider different possible interpretations of the speech and select the one that best matches the acoustic signal and the linguistic context.
- Speaker Diarization: Beam search can be used to identify and segment speech from different speakers in a recording. It helps the system distinguish between multiple voices and assign each speaker their corresponding segments.