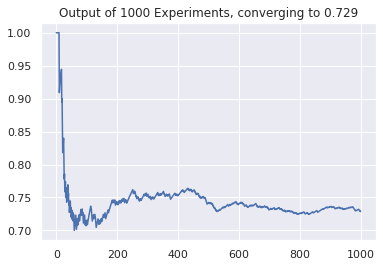
If you get on a plane that can carry 100 or more passengers at a time, there is a 99% chance that one of the passengers shares the same birthday as yours. If you get into a bus with a capacity of 50 passengers, you have a 97% chance of finding someone who shares your […]
Birthday Problem and Monte Carlo Simulation