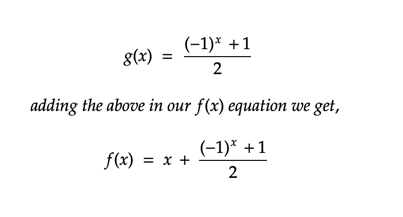For any function, We want, for every value of x, return the corresponding odd number. If x is odd then return it as it is, else return the next number. This can easily be done using a computer program by checking if the number is odd or even. But if you had to find a […]
Function to get the preceding odd number (y) for any given number (x)