
In character recognition, the distance between two edges of a stroke, measured perpendicular to the stroke centerline is called the stroke width. Take a look at the below image. The length of lines marked in Red gives the stroke width of the character.

There are quite a few ways to identify the stroke width, In this article I will talk about the one based on distance transform. Distance transform when applied to a binary image gives us an image where each pixel represents it’s distance from the nearest 0 value pixel.
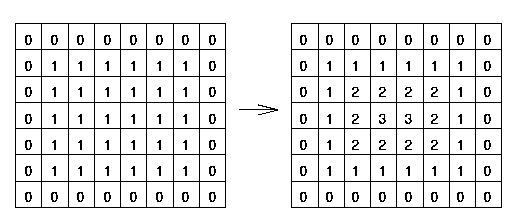
As you can visually calculate, the stroke width in case of the above image is 6. The value at the center in the DT image is 3 that’s because the pixel is 3 units away from the closest 0 value pixel. So we can conclude that given a binary image, the stroke width is the mean of center pixels multipied by 2. And now to find the center pixels we can skeletonize the image which will give use a boolean mask with center pixles marked as True.

Once we have boolean mask, we can easily pick the values of center pixels from the DT image. Python code that does all of this is given below:
from skimage.io import imread
from skimage.color import rgb2gray
from skimage.filters import threshold_otsu
from scipy.ndimage.morphology import distance_transform_edt
from skimage.morphology import skeletonize
import numpy as np
# load the image
img = imread("https://muthu.co/wp-content/uploads/2020/09/char.png")
# convert the image to grayscale
gray = rgb2gray(img)
# thresholding the image to binary
threshold = threshold_otsu(gray)
binary_image = gray > threshold
# add some padding to the image to
# avoid wrong distance calculations for corner pixels
padded_image = np.pad(binary_image, 2)
# find the distance transform
distances = distance_transform_edt(padded_image)
# skeletonize the image to find the center pixels
skeleton = skeletonize(padded_image)
# find the center pixel distances
center_pixel_distances = distances[skeleton]
# get the stroke width, twice the average of center pixel distances
stroke_width = np.mean(center_pixel_distances) * 2
print(stroke_width)
# show the image
plt.figure(figsize=(10,10))
plt.imshow(padded_image, cmap="gray")References: