
In response to the growing usage of our windows application and the need to enhance its performance, our development team embarked on a project to refactor our legacy C# codebase. A key focus of this effort was to streamline the application’s memory usage to ensure optimal performance and scalability. Recognizing that inefficient memory management can significantly impact the application’s responsiveness and overall user experience, we undertook thorough research and collaborative brainstorming sessions to pinpoint the most effective strategies for optimizing RAM consumption.
Through our analysis, we uncovered several areas within the codebase where memory inefficiencies were prevalent. These inefficiencies ranged from redundant data structures to suboptimal algorithms and memory leaks. Addressing these issues became paramount in our quest to enhance the application’s efficiency and responsiveness.
After careful consideration and experimentation, we distilled our findings into a set of best practices and optimization techniques tailored to our specific use case and technology stack. These techniques are designed not only to reduce RAM consumption but also to improve the application’s performance and stability.
In the following sections, I will outline the key strategies that emerged from our research. These strategies represent our roadmap for optimizing RAM and CPU usage in our C# application, encompassing both low-level memory optimizations and high-level architectural improvements. By implementing these strategies conscientiously, we aim to achieve a leaner, more efficient application that can meet the evolving needs of our users while maintaining high standards of performance and reliability.
Hashset vs List
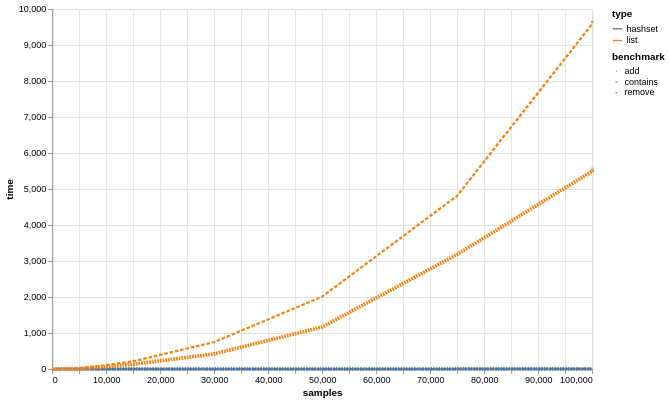
Theoretically, a Hashset is better than a List, we decided to prove it through some benchmarking. We simulated and ran a series of operations on both a HashSet and a List. These operations included adding elements, checking for element existence, and removing elements. What we found was both intriguing and insightful. As the dataset size grew, the performance of the List started to lag behind significantly. Each operation took longer to complete, and the time it took increased exponentially with the size of the dataset. On the other hand, the HashSet remained steadfast and consistent, delivering comparable performance across all operations, regardless of dataset size.
The result is as shown below: you can clearly see that the List performs poorly as the data size increases, while the Hashset takes nearly the same time for all operations
This the code we used to create this benchmark.
using Newtonsoft.Json;
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.IO;
using System.Linq;
namespace ConsoleApp1
{
internal static class Program
{
private static List<object> results = new List<object>();
public static void Main(string[] args)
{
// Number of elements for benchmarking
int[] dataSize = new int[] { 10, 100, 1000, 5000, 10000, 15000, 30000, 50000, 75000, 100000, 100000 };
foreach (int count in dataSize)
{
BenchmarkAdd(count);
BenchmarkContains(count);
BenchmarkRemove(count);
}
File.WriteAllText("results.json", JsonConvert.SerializeObject(results));
}
private static void BenchmarkAdd(int count)
{
Stopwatch sw = Stopwatch.StartNew();
HashSet<int> hashSet = new HashSet<int>();
for (int i = 0; i < count; i++)
{
hashSet.Add(i);
}
sw.Stop();
results.Add(new
{
type = "hashset",
benchmark = "add",
samples = count,
time = sw.ElapsedMilliseconds
});
Console.WriteLine("HashSet Add: {0} ms", sw.ElapsedMilliseconds);
sw.Restart();
List<int> list = new List<int>();
for (int i = 0; i < count; i++)
{
list.Add(i);
}
sw.Stop();
results.Add(new
{
type = "list",
benchmark = "add",
samples = count,
time = sw.ElapsedMilliseconds
});
Console.WriteLine("List Add: {0} ms", sw.ElapsedMilliseconds);
}
private static void BenchmarkContains(int count)
{
List<int> list = Enumerable.Range(0, count).ToList();
HashSet<int> hashSet = new HashSet<int>(list);
// search for value in hashset
Stopwatch sw = Stopwatch.StartNew();
for (int i = 0; i < count; i++)
{
hashSet.Contains(i);
}
sw.Stop();
results.Add(new
{
type = "hashset",
benchmark = "contains",
samples = count,
time = sw.ElapsedMilliseconds
});
Console.WriteLine("HashSet Contains: {0} ms", sw.ElapsedMilliseconds);
sw.Restart();
// search for value in list
for (int i = 0; i < count; i++)
{
list.Contains(i);
}
sw.Stop();
results.Add(new
{
type = "list",
benchmark = "contains",
samples = count,
time = sw.ElapsedMilliseconds
});
Console.WriteLine("List Contains: {0} ms", sw.ElapsedMilliseconds);
}
private static void BenchmarkRemove(int count)
{
List<int> list = Enumerable.Range(0, count).ToList();
HashSet<int> hashSet = new HashSet<int>(list);
Stopwatch sw = Stopwatch.StartNew();
for (int i = 0; i < count; i++)
{
hashSet.Remove(i);
}
sw.Stop();
results.Add(new
{
type = "hashset",
benchmark = "remove",
samples = count,
time = sw.ElapsedMilliseconds
});
Console.WriteLine("HashSet Remove: {0} ms", sw.ElapsedMilliseconds);
sw.Restart();
for (int i = 0; i < count; i++)
{
list.Remove(i);
}
sw.Stop();
results.Add(new
{
type = "list",
benchmark = "remove",
samples = count,
time = sw.ElapsedMilliseconds
});
Console.WriteLine("List Remove: {0} ms", sw.ElapsedMilliseconds);
}
}
}In summary, here is a simple difference between suboptimal and optimized approach.
Suboptimal Approach:
List<int> numbers = new List<int>(); // Using a List to store numbers
// Adding numbers to the list
numbers.Add(10);
numbers.Add(20);
numbers.Add(30);
// Performing search operation
int index = numbers.IndexOf(20); // Search for an element in the list
While a List provides dynamic resizing and various useful methods, it might not be the most efficient for frequent search operations. The IndexOf method performs a linear search, resulting in O(n) time complexity.
Optimized Approach:
using System;
using System.Collections.Generic;
class Program
{
static void Main()
{
// Optimized code using HashSet<int> for faster search
// Using a HashSet<int> instead of List<int>
HashSet<int> numbers = new HashSet<int>();
// Adding numbers to the HashSet
numbers.Add(10);
numbers.Add(20);
numbers.Add(30);
// Performing search operation
bool contains20 = numbers.Contains(20);
}
}Using a HashSet for this scenario improves the search operation efficiency to O(1) on average, offering faster lookups for large collections due to its hashing-based data structure.
Lookup Operations in Dictionary
Suppose you frequently need to search for associated values based on keys. It’s common practice to check if the key exists before retrieving its value from the dictionary. While this approach is harmless, we’ve discovered a more optimal alternative: utilizing the TryGetValue method of the dictionary.
TryGetValue method in C# is preferred over directly accessing a key in a dictionary because of its safety and performance benefits.
-
Safety: When you access a key directly in a dictionary using indexing (e.g.,
myDictionary[key]), if the key does not exist in the dictionary, it will throw aKeyNotFoundExceptionexception. On the other hand,TryGetValuemethod returns a boolean indicating whether the key exists in the dictionary or not, and if it does, it also retrieves the corresponding value. This prevents your code from throwing exceptions, making it safer and more robust. -
Performance:
TryGetValuemethod provides better performance compared to directly accessing a key, especially when dealing with large dictionaries or when you’re uncertain about whether a key exists. Directly accessing a key requires the dictionary to compute the hash of the key and perform a lookup operation, which can be expensive, especially if the key doesn’t exist.TryGetValue, however, performs these operations more efficiently, avoiding redundant computations and improving overall performance.
Here’s an example illustrating the usage of TryGetValue:
Dictionary<string, int> myDictionary = new Dictionary<string, int>();
// Directly accessing a key (not recommended)
try
{
int value = myDictionary["key"];
Console.WriteLine("Value: " + value);
}
catch (KeyNotFoundException)
{
Console.WriteLine("Key not found.");
}
// Using TryGetValue (recommended)
int result;
if (myDictionary.TryGetValue("key", out result))
{
Console.WriteLine("Value: " + result);
}
else
{
Console.WriteLine("Key not found.");
}In this example, the second approach using TryGetValue is safer and more efficient, as it handles the case where the key doesn’t exist without throwing an exception and provides better performance, especially for large dictionaries.
Avoid general purpose collections when there is a use case specific collection
Suppose you require a data structure for first-in-first-out (FIFO) operations. This can be achieved using a List as shown in the code below:
List<int> queue = new List<int>(); // Using a List as a queue
// Enqueue elements
queue.Add(5);
queue.Add(10);
// Dequeue operation
int firstElement = queue[0];
queue.RemoveAt(0);
Using a List for a queue might result in inefficient dequeue operations (RemoveAt) due to shifting elements.
Optimized Approach:
Queue<int> queue = new Queue<int>(); // Using Queue for FIFO operations
// Enqueue elements
queue.Enqueue(5);
queue.Enqueue(10);
// Dequeue operation
int firstElement = queue.Dequeue(); // Remove and retrieve the first element
Here’s an elaboration on why using a List as a queue is suboptimal and how Queue is the optimized approach:
List vs. Queue:
-
Purpose: A
Listis designed for general-purpose collections, allowing insertion and removal from anywhere. AQueuespecifically focuses on FIFO (First-In-First-Out) operations, where elements are enqueued at the end and dequeued from the beginning. -
Efficiency: Dequeueing from a
Listrequires shifting all remaining elements down one position, leading toO(n)time complexity, wherenis the number of elements. In contrast, aQueueuses internal pointers to directly access the first and last elements, achievingO(1)time complexity for both enqueue and dequeue operations. -
Memory overhead: A
Listonly stores the data values, while aQueuemight have additional fields for managing pointers and internal state, potentially leading to slightly higher memory usage.
Consequences of using a List as a queue:
-
Performance bottleneck: Repeated dequeue operations become increasingly slower as the queue grows due to the
O(n)complexity. -
Unexpected behavior: If other code accesses or modifies the
Listdirectly, it can disrupt the queue’s expected behavior and lead to incorrect results. -
Debugging challenges: Troubleshooting issues with a
Listmasquerading as a queue can be difficult due to the lack of explicit FIFO semantics.
Benefits of using Queue:
- Efficiency: Both enqueue and dequeue operations are fast and consistent, regardless of queue size.
- Clarity: Using the appropriate data structure clearly communicates the intent of your code and makes it easier to understand and maintain.
-
Safety: The
Queueclass enforces FIFO behavior, preventing accidental modifications that could violate the queue’s order.
Additional considerations:
- For very small queues, the performance difference between
ListandQueuemight be negligible. - If concurrent access to the queue is required, consider using a thread-safe
ConcurrentQueueimplementation.
In conclusion, using a Queue is the better choice for implementing FIFO operations due to its efficiency, clarity, and safety advantages. Avoid using a List as a queue unless you have specific reasons for prioritizing simplicity over optimal performance and behavior.
Arrays vs. Lists
Use arrays when you know the size of the data collection in advance and need fast random access to elements. They have a fixed size and occupy a contiguous block of memory. Take a look at the example below:
List<int> numbers = new List<int>(); // Initially empty
for (int i = 0; i < 10000; i++)
{
numbers.Add(i); // Dynamically adds elements, might trigger resizing
}
// Access elements, but might involve internal overhead
int valueAt500 = numbers[500];Optimized Approach:
int[] numbers = new int[10000]; // Allocate a fixed block of 10000 integers
for (int i = 0; i < numbers.Length; i++)
{
numbers[i] = i;
}
// Access elements directly, no additional memory overhead
int valueAt500 = numbers[500];
Array vs List
- Memory Allocation: Arrays allocate a single contiguous block of memory upfront, while lists dynamically allocate memory as needed, potentially leading to fragmentation.
- Resizing: Arrays have a fixed size, while lists can grow or shrink. Resizing lists can involve reallocating memory and copying elements, affecting performance.
- Element Access: Arrays provide constant-time random access to elements by index, while lists might have slightly slower access due to internal overhead.
StringBuilder vs. String Concatenation
Use StringBuilder for repeated string concatenations, especially in loops. It’s more efficient than using the + operator, which creates new string objects each time.
Here’s a code example demonstrating the importance of StringBuilder vs. String Concatenation in RAM memory optimization:
using System;
namespace StringConcatenationDemo
{
class Program
{
static void Main(string[] args)
{
// Inefficient string concatenation using the + operator
string combinedString = "";
for (int i = 0; i < 100000; i++)
{
combinedString += i.ToString(); // Creates a new string object for each iteration
}
// Efficient string building using StringBuilder
StringBuilder builder = new StringBuilder();
for (int i = 0; i < 100000; i++)
{
builder.Append(i.ToString()); // Appends to existing buffer
}
// Creates the final string only once
string finalString = builder.ToString();
}
}
}
Explanation:
-
String Concatenation with +:
- In each loop iteration, a new string object is created to hold the combined value of
combinedStringand the currenti.ToString(). - This leads to numerous string objects being allocated in memory, eventually leading to garbage collection overhead and potential performance issues.
- In each loop iteration, a new string object is created to hold the combined value of
-
StringBuilder:
- The
StringBuilderobject maintains an internal buffer to efficiently handle string manipulations. - The
Append()method appends text to the existing buffer, avoiding the creation of new string objects for each iteration. - The final string is created only once, when
ToString()is called, reducing memory usage significantly.
- The
Key Points:
-
String Immutability: In C#, strings are immutable, meaning their contents cannot be changed after creation. Concatenation using
+actually creates a new string object with the combined content. -
StringBuilder Efficiency:
StringBuilderis specifically designed for efficient string manipulation, avoiding unnecessary object creation and memory allocation.
Structs vs. Classes
Consider using structs for small, lightweight data structures that primarily hold data without complex behavior. They are value types, stored directly on the stack, and can reduce memory overhead compared to classes in certain cases.
Here’s a code example demonstrating the importance of Structs vs. Classes in RAM memory optimization:
using System;
namespace StructVsClassDemo
{
// Class representation
class PointAsClass
{
public int X { get; set; }
public int Y { get; set; }
}
// Struct representation
struct PointAsStruct
{
public int X;
public int Y;
}
class Program
{
static void Main(string[] args)
{
// Create 100000 points using classes
PointAsClass[] pointsAsClasses = new PointAsClass[100000];
for (int i = 0; i < 100000; i++)
{
pointsAsClasses[i] = new PointAsClass() { X = i, Y = i * 2 };
}
// Create 100000 points using structs
PointAsStruct[] pointsAsStructs = new PointAsStruct[100000];
for (int i = 0; i < 100000; i++)
{
pointsAsStructs[i] = new PointAsStruct() { X = i, Y = i * 2 };
}
}
}
}
Explanation:
-
Memory Allocation:
- Classes: Instances are allocated on the heap, which involves additional overhead for memory management and garbage collection.
- Structs: Instances are typically allocated on the stack, which is a more efficient memory region for small, short-lived objects.
-
Memory Overhead:
- Classes: Each object has a hidden reference overhead (4 or 8 bytes, depending on architecture) that points to its location on the heap.
- Structs: Structs don’t have this reference overhead, storing their values directly within the array or variable.
-
Copying Behavior:
- Classes: When you pass a class instance to a method or assign it to another variable, a reference to the object is copied, not the object itself.
- Structs: Structs are copied by value, meaning a new copy of the struct’s data is created, ensuring data integrity but potentially affecting performance for large structs.
Key Points:
- Choose structs: For simple data structures that primarily hold data without complex behavior and are frequently created and destroyed.
- Choose classes: For objects that encapsulate behavior, need to be passed by reference, or require inheritance and polymorphism.
-
Consider:
- Size: Structs should be relatively small (ideally less than 16 bytes) to avoid potential allocation on the heap.
- Immutability: Structs are often designed to be immutable for thread-safety and clarity.
- Performance vs. Memory Trade-offs: Profile your code to make informed choices based on your specific requirements.
Avoid Global Variables
Avoiding global variables in C# involves encapsulating data within classes or passing data explicitly between methods. We moved many static global variables to local variables, this change did not bring in huge improvements but we do know it did add up a bit to the overall improvements that we did. Here’s an example that demonstrates how to avoid global variables by using a class to encapsulate data:
using System;
public class DataProcessor
{
private int globalValue; // Global variable replaced by an instance variable
public DataProcessor(int initialValue)
{
this.globalValue = initialValue;
}
public void ProcessData()
{
// Perform data processing using the encapsulated value
Console.WriteLine($"Processing data with value: {globalValue}");
}
// Other methods can use the encapsulated data as needed
public void SetGlobalValue(int newValue)
{
// Setter method to modify the encapsulated value
this.globalValue = newValue;
}
}
class Program
{
static void Main()
{
// Create an instance of DataProcessor
DataProcessor dataProcessor = new DataProcessor(initialValue: 42);
// Call methods on the instance, avoiding global variables
dataProcessor.ProcessData();
// Modify the encapsulated value using a setter method
dataProcessor.SetGlobalValue(newValue: 99);
// Call the processing method again with the updated value
dataProcessor.ProcessData();
}
}In this example:
- The
DataProcessorclass encapsulates the global value within a private instance variable. - The
ProcessDatamethod operates on the encapsulated data without relying on a global variable. - The
SetGlobalValuemethod provides a way to modify the encapsulated value.
By using a class and encapsulating data within it, you avoid the use of global variables and promote better organization and encapsulation of your code.
Optimize Large Data Processing
Optimizing large data processing in C# often involves processing data in smaller chunks to avoid loading the entire dataset into memory at once. Here’s an example that demonstrates how to process large data in chunks:
using System;
using System.Collections.Generic;
using System.IO;
public class LargeDataProcessor
{
// Process data in chunks to optimize memory usage
public void ProcessLargeData(string filePath, int chunkSize)
{
using (FileStream fileStream = new FileStream(filePath, FileMode.Open, FileAccess.Read))
using (StreamReader reader = new StreamReader(fileStream))
{
char[] buffer = new char[chunkSize];
int bytesRead;
do
{
bytesRead = reader.Read(buffer, 0, buffer.Length);
// Process the current chunk of data
ProcessChunk(buffer, bytesRead);
} while (bytesRead == buffer.Length);
}
}
// Method to process a chunk of data
private void ProcessChunk(char[] dataChunk, int length)
{
// Perform processing on the current chunk of data
Console.WriteLine($"Processing chunk of size {length}: {new string(dataChunk, 0, length)}");
}
}
class Program
{
static void Main()
{
// Example: Process a large file in chunks
LargeDataProcessor dataProcessor = new LargeDataProcessor();
// Specify the file path and the desired chunk size
string filePath = "large_data.txt";
int chunkSize = 1024; // Adjust the chunk size based on your requirements
// Process the large data file in chunks
dataProcessor.ProcessLargeData(filePath, chunkSize);
}
}In this example:
- The
LargeDataProcessorclass contains a methodProcessLargeDatathat reads the data from a file in chunks. - The
ProcessChunkmethod is called for each chunk of data read from the file, allowing you to process the data without loading the entire file into memory at once. - The file is read using a
FileStreamandStreamReader, and the data is processed in chunks specified by thechunkSizeparameter.
Adjust the chunkSize based on your specific requirements and available memory. This approach helps optimize memory usage when dealing with large datasets, as it avoids loading the entire dataset into memory, which can lead to increased memory consumption and potential performance issues.
Limit the Use of Finalizers
In C#, finalizers are special methods that are part of the .NET garbage collection system. They are invoked by the garbage collector before an object is reclaimed, providing an opportunity to release unmanaged resources or perform cleanup operations. While finalizers can be useful for certain scenarios, it’s important to be cautious about their usage due to several reasons:
Non-deterministic Execution:
- Finalizers are non-deterministic, meaning you don’t have control over when they will be executed. They are invoked by the garbage collector during its collection cycles, which are non-predictable. This lack of determinism can lead to uncertainty regarding the timing of resource cleanup.
Performance Overhead:
- Finalizers add performance overhead to the garbage collection process. The .NET garbage collector has to perform additional work to identify and execute finalizers, potentially impacting the overall performance of your application.
Resource Leaks:
- If the finalizer doesn’t release resources promptly or encounters an exception, it might lead to resource leaks. Resources like file handles, network connections, or database connections may not be released in a timely manner, impacting the overall system’s stability.
Unreliable for Memory Management:
- Relying solely on finalizers for managing resources is not a reliable strategy. It’s better to use deterministic cleanup methods, such as implementing the
IDisposableinterface and callingDispose()explicitly.
Given these considerations, here are some best practices for managing finalizers:
Implement IDisposable for Resource Cleanup – Instead of relying solely on finalizers, implement the IDisposable interface for explicit resource cleanup. This allows you to use the using statement to ensure timely disposal of resources.
public class MyClass : IDisposable
{
private bool disposed = false;
public void Dispose()
{
Dispose(true);
GC.SuppressFinalize(this);
}
protected virtual void Dispose(bool disposing)
{
if (!disposed)
{
if (disposing)
{
// Dispose of managed resources
}
// Dispose of unmanaged resources
disposed = true;
}
}
~MyClass()
{
Dispose(false);
}
}
Use Finalizers Sparingly – Limit the use of finalizers to scenarios where explicit resource cleanup is necessary, and alternatives are not feasible. Finalizers should be a last resort rather than a primary mechanism for resource management.
Consider SafeHandle or CriticalFinalizerObject – If your class needs to deal with unmanaged resources, consider using the SafeHandle class or deriving from CriticalFinalizerObject to ensure more reliable resource cleanup.
Dispose of unused objects
Disposing of unused objects in C# is crucial for efficient memory management and preventing resource leaks. Imagine you have a program that reads data from a file. To access the file, you create a FileStream object. This object holds a reference to the actual file and consumes system resources.
Without Disposing:
- You open the file and read the data using
FileStream. - You finish reading and move on, but forget to close the file.
- The
FileStreamobject remains in memory, even though you’re not using it anymore. - Over time, if you open many files without closing them, memory usage keeps increasing, potentially leading to performance issues and even crashes.
using System.IO;
class Program
{
static void Main(string[] args)
{
// Open the file using FileStream
FileStream stream = File.OpenRead("data.txt");
// Read data from the file (assuming you have a data-reading logic here)
// ...
// Move on to other tasks, but the file remains open
// ...
// The FileStream object is not explicitly disposed, potentially leading to resource leaks
}
}
With Disposing:
- You open the file and read the data using
FileStream. - When you finish reading, you explicitly call
Dispose()on theFileStreamobject. - This signals the system to release the resources associated with the file, effectively closing it.
- The memory used by the
FileStreamis now available for other tasks.
// With disposing:
using (FileStream stream = File.OpenRead("data.txt"))
{
// Read data from the file
}
// The stream is automatically disposed at the end of the using block
// OR
FileStream stream = File.OpenRead("data.txt");
try
{
// Read data from the file
}
finally
{
stream.Dispose(); // Remember to dispose even if there are exceptions
}- Look for objects that implement the
IDisposableinterface, as these typically need explicit disposal. - Use the
usingstatement whenever possible, as it automatically disposes of the object when the code block exits. - Be mindful of nested objects and dispose them in the correct order.
- Use memory profilers to identify potential memory leaks and pinpoint objects that might need proper disposal.
Be mindful of collections
Favor List<T> for dynamic collections, but consider Span<T> or Array for fixed-size data. Avoid boxing primitives by using value types for collection elements.
Favor List for Dynamic Collections:
When dealing with dynamic collections where the size may change frequently, the List<T> class is often a good choice. It provides dynamic resizing and many helpful methods for working with collections.
Example:
using System;
using System.Collections.Generic;
class Program
{
static void Main()
{
// Favor List<T> for dynamic collections
List<int> dynamicList = new List<int>();
dynamicList.Add(1);
dynamicList.Add(2);
dynamicList.Add(3);
Console.WriteLine("Dynamic List:");
foreach (var item in dynamicList)
{
Console.WriteLine(item);
}
}
}In this example, a List<int> is used to create a dynamic collection of integers. The List<T> provides methods like Add for easily appending elements and is efficient for scenarios where the size of the collection may change.
Consider Span or Array for Fixed-Size Data:
For collections with a fixed size, or when dealing with contiguous blocks of memory, consider using Span<T> or arrays. These types offer better performance in certain scenarios and might be more suitable for working with fixed-size data.
Example using Array:
using System;
class Program
{
static void Main()
{
// Consider Array for fixed-size data
int[] fixedSizeArray = new int[3] { 1, 2, 3 };
Console.WriteLine("Fixed-Size Array:");
foreach (var item in fixedSizeArray)
{
Console.WriteLine(item);
}
}
}In this example, an array int[] is used to create a fixed-size collection. Arrays have a fixed size once allocated, and their memory layout is contiguous, making them suitable for scenarios where the size is known in advance.
Example using Span:
using System;
class Program
{
static void Main()
{
// Consider Span<T> for fixed-size data or contiguous memory
int[] data = new int[] { 1, 2, 3 };
Span<int> fixedSizeSpan = data.AsSpan();
Console.WriteLine("Fixed-Size Span:");
foreach (var item in fixedSizeSpan)
{
Console.WriteLine(item);
}
}
}In this example, a Span<int> is created from an existing array. Span<T> provides a view into the memory, and it can be more efficient than arrays for certain operations, especially when working with contiguous memory.
Avoid Boxing Primitives:
When working with collections, it’s important to avoid unnecessary boxing of primitive types. Boxing involves converting a value type to a reference type, which can lead to performance overhead.
Example:
using System;
using System.Collections.Generic;
class Program
{
static void Main()
{
// Avoid boxing primitives in collections
List<int> listOfIntegers = new List<int>();
listOfIntegers.Add(42);
// This will cause boxing: int to object
object boxedInt = listOfIntegers[0];
Console.WriteLine($"Boxed Integer: {boxedInt}");
}
}In this example, the code adds an int to a List<int>, but then it boxes the integer by assigning it to an object. Avoiding such boxing can be achieved by using generic collections like List<T>.
Avoid unnecessary allocations
This is lesser known advice but can be crucial for improving the performance of your code, especially in scenarios where memory allocation and deallocation are frequent. The advice is to use Span<T> or ReadOnlySpan<T> instead of full strings for temporary operations. Let’s go through an example to illustrate this concept:
using System;
class Program
{
static void Main()
{
// Avoid unnecessary allocations: Use Span<T> or ReadOnlySpan<T> for temporary operations
// Scenario 1: Using full strings
string firstName = "John";
string lastName = "Doe";
// Concatenating strings creates a new string object
string fullNameString = ConcatenateStrings(firstName, lastName);
Console.WriteLine("Full Name (using strings): " + fullNameString);
// Scenario 2: Using Span<T>
ReadOnlySpan<char> firstNameSpan = "John".AsSpan();
ReadOnlySpan<char> lastNameSpan = "Doe".AsSpan();
// Combining spans directly without creating new strings
ReadOnlySpan<char> fullNameSpan = ConcatenateSpans(firstNameSpan, lastNameSpan);
Console.WriteLine("Full Name (using spans): " + fullNameSpan.ToString());
}
// Concatenating strings creates a new string object
static string ConcatenateStrings(string firstName, string lastName)
{
return firstName + " " + lastName;
}
// Combining spans directly without creating new strings
static ReadOnlySpan<char> ConcatenateSpans(ReadOnlySpan<char> firstName, ReadOnlySpan<char> lastName)
{
// + operator is not directly applicable to spans, so we use Slice and Concatenate
Span<char> result = new char[firstName.Length + lastName.Length];
firstName.CopyTo(result);
lastName.CopyTo(result.Slice(firstName.Length));
return result;
}
}In this example:
- In Scenario 1, we concatenate two strings (
firstNameandlastName) to create a full name. Each concatenation operation creates a new string object. - In Scenario 2, we use
ReadOnlySpan<char>to represent the character spans forfirstNameandlastName. We then concatenate these spans directly without creating new strings.
Using spans directly can help avoid unnecessary allocations and improve performance in scenarios where temporary data is involved. However, it’s important to note that the specific approach might vary depending on the context and requirements of your application. Spans are particularly useful for scenarios involving large data sets or when performance is a critical concern.