
Lets say I give you a print out of Professor Albert Einstein’s Wikipedia page and tell you that I am going to ask you questions from that text. You will have enough time to read through the document and find the answers that I am looking for. Assuming you are good at finding answers, here is what our conversation may look like.
Me - When did Albert Einstein win the Nobel prize for physics? You - 1921 Me - What was Einstein age when he died? You - 76 Me - How many children did Einstein have? You - 3, Eduard Einstein, Lieserl Einstein, Hans Albert Einstein Me - Which musical instrument did Einstein play? You - Violin Me - What did Einstein receive the Nobel prize for? You - for his services to Theoretical Physics, and especially for his discovery of the law of the photoelectric effect
For a human mind to do this task is fairly easy but for a machine it takes a lot more than just feeding in the document and running a text search. This is what I am trying to build, an intelligent machine programmed to extract facts from documents and organize them in its memory and provide answers to questions given in natural language. I call him Grus.
How is it different from other search engines? Take a look at the below snapshot.
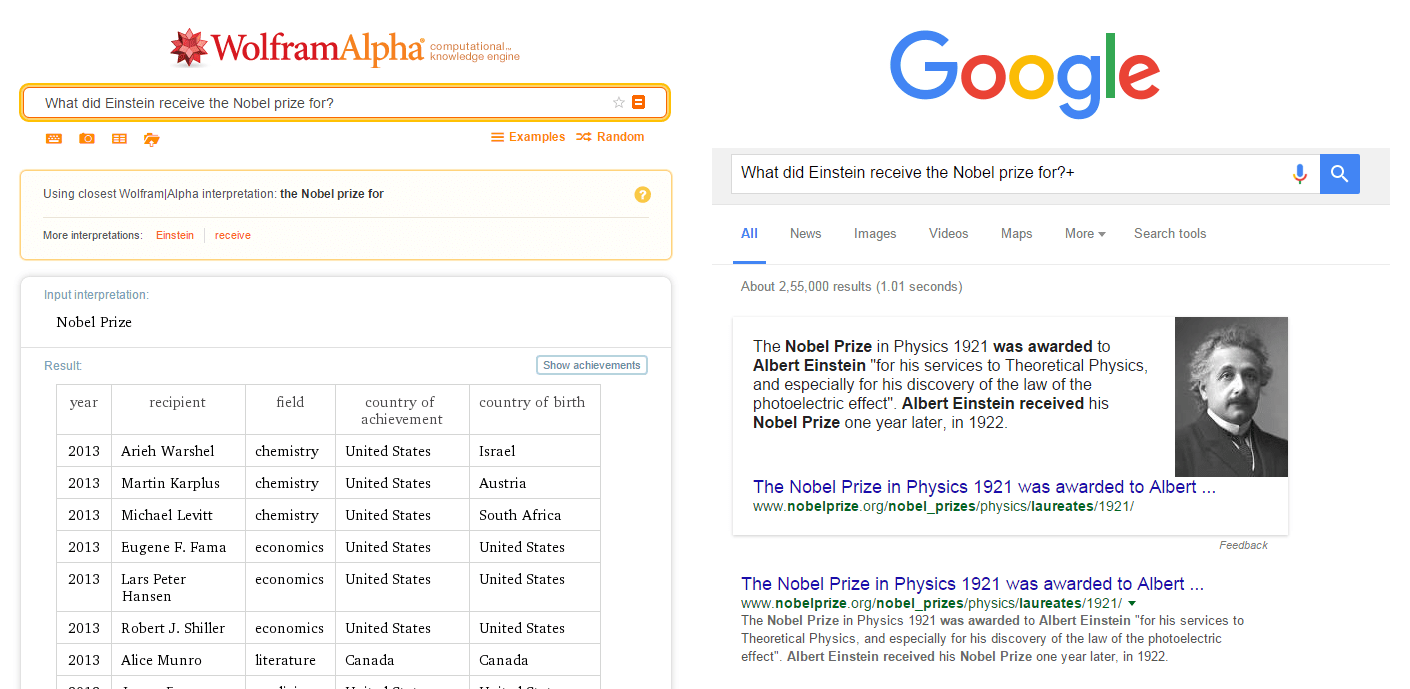
WolframAlpha had no clue what I am trying to find while Google was lucky to find the exact text match in one of the pages so was able to come back with the relevant links.
Here is another example.
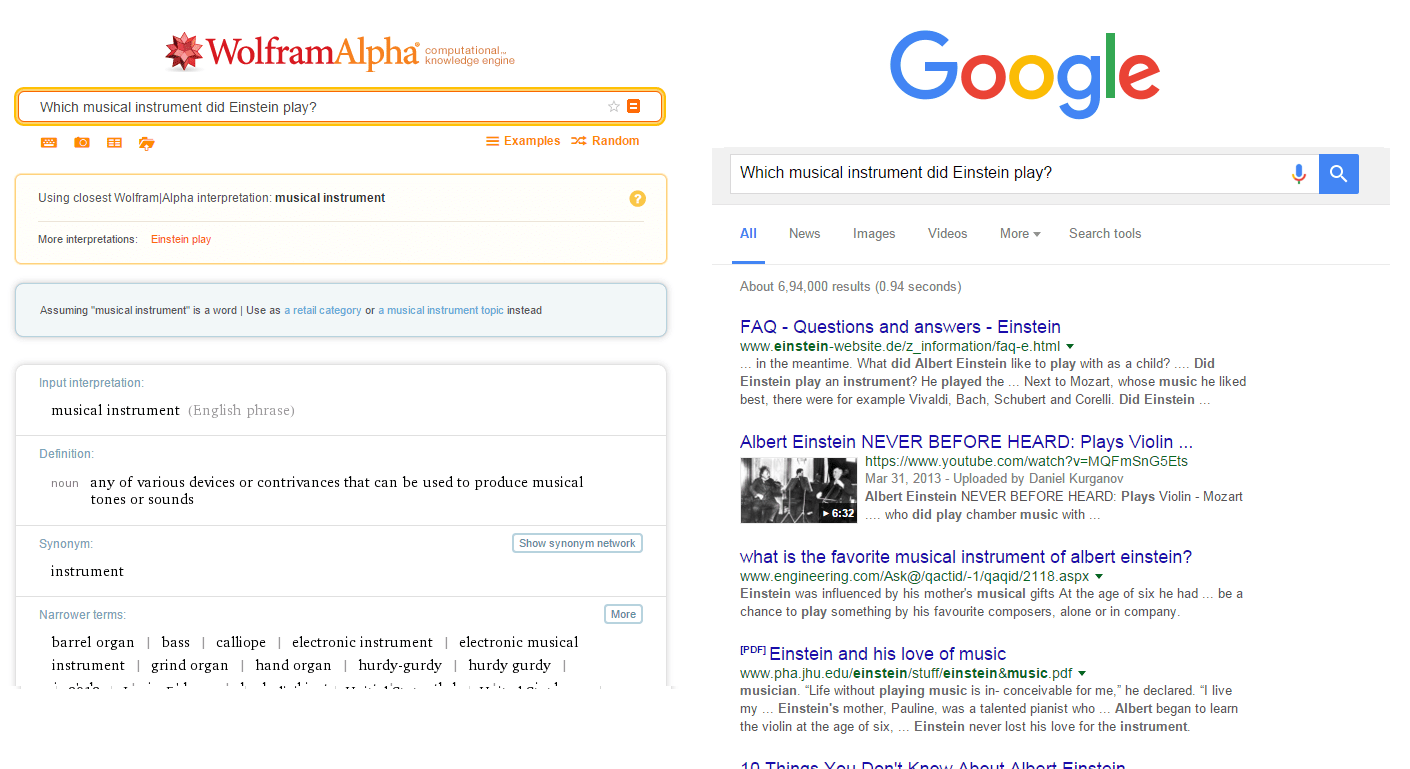
This time neither WolframAlpha nor Google could figure out what I am trying to ask. While its easy to go through the links and find the answer but is it worth the time? Why can’t I just have a one word answer to my question?
Watch this space for more info on the progress of Grus (grus.io) – An intelligent question answering machine.