The SOLID principles are a set of five design principles in object-oriented programming intended to make software designs more understandable, flexible, and maintainable. These principles were introduced by Robert C. Martin (also known as Uncle Bob) and are considered fundamental guidelines for creating high-quality, robust, and scalable software systems.
SOLID stands for:
S – Single-Responsiblity Principle
O – Open-closed Principle
L – Liskov Substitution Principle
I – Interface Segregation Principle
D – Dependency Inversion Principle
Single Responsibility Principle (SRP)
| A class should have only one reason to change | |
| What it means | It should encapsulate one and only one aspect of functionality. |
| Application | Design classes to perform a single, well-defined task, making them focused, easier to understand, test, and maintain. |
To understand this concept in detail, let’s build an Area Calculator application that takes in a list of shapes and calculates their total area.
Let’s start by creating a class to represent our squares, which takes the length of its side as a constructor parameter.

class Square {
// Use double for precision with area calculations
private double sideLength;
public Square(double sideLength) {
this.sideLength = sideLength;
}
public double getArea() {
// Calculate area as sideLength squared
return Math.pow(sideLength, 2);
}
}For circles, you will need to know the radius:

class Circle {
// Use double for precision with area calculations
private double radius;
public Circle(double radius) {
this.radius = radius;
}
public double getArea() {
// Calculate area using Pi and radius squared
return Math.PI * Math.pow(radius, 2);
}
}
To find the total area covered by all our shapes, we’ll build an AreaCalculator class, which will know how to calculate the area of each shape, whether it’s a Square or a Circle.

class AreaCalculator {
private List<Object> shapes;
public AreaCalculator(List<Object> shapes) {
this.shapes = shapes;
}
public double calculateTotalArea() {
double totalArea = 0;
for (Object shape : shapes) {
if (shape instanceof Square) {
Square square = (Square) shape;
totalArea += square.getArea();
} else if (shape instanceof Circle) {
Circle circle = (Circle) shape;
totalArea += circle.getArea();
} else {
throw new IllegalArgumentException("Unsupported shape type");
}
}
return totalArea;
}
public String printAreaSummary() {
return String.format("Sum of the areas of provided shapes: %.2f\n", calculateTotalArea());
}
}If you look carefully, you’ll see that the AreaCalculator class does two things:
- it calculates the area of shapes and
- handles printing the total area.
If you want to display the area information differently, you might need to modify the printAreaSummary method. This could involve formatting the output string differently, or even returning the areas for each shape individually instead of a single sum.
The purpose of the AreaCalculator should be solely to calculate the area (adhering to the Single Responsibility Principle). The only reason it should ever change is when we want to support more types of shapes.
Therefore, let’s move the printing responsibility to a separate class called AreaPrinter.
class AreaPrinter {
// Use final for immutability
private final AreaCalculator calculator;
public AreaPrinter(AreaCalculator calculator) {
this.calculator = calculator;
}
public String getJSON() {
// Use Map for clearer data structure
Map<String, Double> data = new HashMap<>();
data.put("sum", calculator.calculateTotalArea());
// Use appropriate JSON encoder library
return JsonUtils.encodeToString(data);
}
public String getHTML() {
return String.format(
"Sum of the areas of provided shapes: %.2f\n",
calculator.calculateTotalArea());
}
}Now, our AreaCalculator class does one thing and one thing only.
class AreaCalculator {
private List<Object> shapes;
public AreaCalculator(List<Object> shapes) {
this.shapes = shapes;
}
public double calculateTotalArea() {
double totalArea = 0;
for (Object shape : shapes) {
if (shape instanceof Square) {
Square square = (Square) shape;
totalArea += square.getArea();
} else if (shape instanceof Circle) {
Circle circle = (Circle) shape;
totalArea += circle.getArea();
} else {
throw new IllegalArgumentException("Unsupported shape type");
}
}
return totalArea;
}
}Open/Closed Principle (OCP)
| Software entities (classes, modules, functions) should be open for extension but closed for modification | |
| What it means | Once a class is written and working, it should be open for extension to add new features, but its existing code should not be modified. |
| Application | Use abstractions (like interfaces or abstract classes) to build a foundation that can be extended without changing existing code. |
The class AreaCalculator we wrote follows the Single responsibilty Principle well but it fails to follow the open/closed principle because:
- Each new shape requires modifying
calculateArea. (modification is open) - Conditional logic becomes complex as more shapes are added. (modification is open)
To make our class OCP-compliant, we should first close the possibility of modification of calculateArea method which we can do using the below steps:
1. Define a Shape interface

interface Shape {
double getArea();
}2. Create Concrete Shape classes
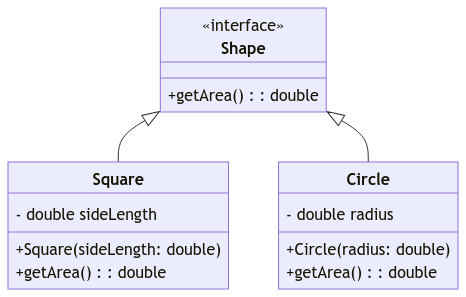
class Square implements Shape {
// Use double for precision with area calculations
private double sideLength;
public Square(double sideLength) {
this.sideLength = sideLength;
}
public double getArea() {
// Calculate area as sideLength squared
return Math.pow(sideLength, 2);
}
}
class Circle implements Shape {
private double radius; // Use double for precision with area calculations
public Circle(double radius) {
this.radius = radius;
}
public double getArea() {
return Math.PI * Math.pow(radius, 2); // Calculate area using Pi and radius squared
}
}
3. Modify the AreaCalculator class
class AreaCalculator {
private List<Shape> shapes;
public AreaCalculator(List<Shape> shapes) {
this.shapes = shapes;
}
public double calculateTotalArea() {
double totalArea = 0;
for (Shape shape : shapes) {
totalArea += shape.getArea();
}
return totalArea;
}
}-
AreaCalculatoris now closed for modification, open for extension. We can extend this class further and add new methods or override the existing method. - Adding new shapes doesn’t require changing
AreaCalculatorclass, it will be automatically supported. - Code is more maintainable, testable, and extensible.
Liskov Substitution Principle (LSP)
| Objects of a superclass should be replaceable with objects of its subclasses without affecting the correctness of the program | |
| What it means | Subtypes must be substitutable for their base types without altering the correctness of the program |
| Application | When inheriting from a class or implementing an interface, ensure that the derived types can be used interchangeably with their base types |
The Liskov Substitution Principle (LSP) plays a crucial role in ensuring the flexibility of software systems. Named after Barbara Liskov, who introduced the principle in 1987, LSP is one of the five SOLID principles that aim to improve the design and maintainability of software.
At its core, the Liskov Substitution Principle articulates the idea of substitutability between objects of different types within an inheritance hierarchy. The principle asserts that if a class (let’s call it S) is a subtype of another class (let’s call it T), instances of class T should be replaceable with instances of class S without altering the correctness of the program. In simpler terms, a child class should seamlessly replace its parent class without introducing errors or modifying the expected behavior of the system.
Imagine a scenario where you have a base class representing a general shape and a derived class representing a specific type of shape, say a square. According to LSP, if square (S) is a subtype of shape (T), you should be able to substitute an instance of the square class wherever an instance of the shape class is expected, without causing any issues.
Let’s consider a scenario involving a Rectangle and a Square, where Square is a subclass of Rectangle. According to classical geometry, a square is a special case of a rectangle where all sides are of equal length. However, implementing this relationship directly might lead to a violation of LSP.
class Rectangle {
protected int width;
protected int height;
public void setWidth(int width) {
this.width = width;
}
public void setHeight(int height) {
this.height = height;
}
public int getArea() {
return this.width * this.height;
}
}
class Square extends Rectangle {
@Override
public void setWidth(int width) {
this.width = width;
this.height = width;
}
@Override
public void setHeight(int height) {
this.height = height;
this.width = height;
}
}In this scenario, a Square is modeled as a subclass of Rectangle. However, by overriding the setWidth() and setHeight() methods in the Square class to set both dimensions to the same value, we violate the LSP. This is because a Square behaves differently than a Rectangle by constraining both width and height to the same value, which is not consistent with the behavior expected from a Rectangle.
Fixing the Code using LSP
To adhere to the Liskov Substitution Principle, it’s essential to reconsider the relationship between Square and Rectangle. Instead of making Square a subclass of Rectangle, let’s refactor the code to remove this inheritance relationship and create separate classes for Square and Rectangle that do not violate the behavior of each other:
class Rectangle {
protected int width;
protected int height;
public Rectangle(int width, int height) {
this.width = width;
this.height = height;
}
public int getArea() {
return this.width * this.height;
}
}
class Square {
private int side;
public Square(int side) {
this.side = side;
}
public int getArea() {
return this.side * this.side;
}
}In this updated code, both Rectangle and Square are separate classes with distinct behaviors. Each class calculates its area based on its specific properties without inheriting from each other. This design adheres to LSP by ensuring that instances of Rectangle and Square do not alter each other’s behavior when used interchangeably.
Why is LSP important? The principle contributes to code reusability, extensibility, and maintainability. When adhering to LSP, developers can confidently extend existing classes without fear of introducing unexpected behaviors or errors. This promotes a modular and scalable codebase, allowing for easier updates and modifications.
Interface Segregation Principle (ISP)
| A client should not be forced to depend on interfaces they do not use | |
| What it means | Split large interfaces into smaller, more specific ones so that clients only need to know about the methods that are of interest to them. |
| Application | Design cohesive and specific interfaces, avoiding “fat” interfaces that force implementing classes to provide unnecessary functionalities |
Imagine you’re building a house. Would you rather have a single, oversized toolbox containing every possible tool you might need, or several smaller, specialized toolkits for specific tasks like carpentry, plumbing, and electrical work? The answer is obvious: smaller focused toolkits make your work more efficient and organized.
The same principle applies to software design also. The Interface Segregation Principle (ISP) tells you to break down large interfaces into smaller, more focused ones based on functionality. This leads to cleaner and more maintainable code. Take for example, the below Fat interface.
interface Machine {
void print();
void scan();
void fax();
}
class MultiFunctionPrinter implements Machine {
@Override
public void print() {
// Printing implementation
}
@Override
public void scan() {
// Scanning implementation
}
// Forced to implement fax(), even though it's not used
@Override
public void fax() {
// Do nothing or throw an exception
}
}The fat Machine interface forces clients (classes implementing the interface) to carry around methods they don’t need, adding unnecessary complexity and weight. This can lead to:
- Increased coupling: Clients become dependent on the entire interface, even for unused methods. This makes them less flexible and harder to reuse in different contexts.
- Code bloat: Unnecessary methods clutter up the codebase, making it harder to understand and maintain.
- Confusion and errors: Developers implementing the interface might mistakenly use the wrong method, leading to unexpected behavior and bugs.
Lets split up the Fat interface into a thinner cohesive interface.
interface Printable {
void print();
}
interface Scannable {
void scan();
}
interface Faxable {
void fax();
}
class MultiFunctionPrinter implements Printable, Scannable {
@Override
public void print() {
// Printing implementation
}
@Override
public void scan() {
// Scanning implementation
}
}
class SimplePrinter implements Printable {
@Override
public void print() {
// Printing implementation
}
}By splitting up fat interfaces into smaller, cohesive interfaces based on functionality, we achieve several benefits:
- Improved clarity: Each interface clearly defines a specific set of related functionalities, making it easier to understand and use.
- Reduced coupling: Clients only need to implement the interfaces that provide the methods they actually use, leading to looser coupling and increased reusability.
- Enhanced maintainability: Smaller interfaces are easier to modify and evolve without impacting other parts of the codebase.
- Developer satisfaction: Working with focused interfaces is more efficient and enjoyable for developers, leading to better code quality and productivity.
The Interface Segregation Principle helps you break down fat interfaces into smaller, focused ones, improving code clarity, and ultimately create software that is easier to understand, use, and maintain.
Dependency Inversion Principle (DIP)
| High-level modules should not depend on low-level modules. Both should depend on abstractions | |
| What it means | Abstractions (interfaces or abstract classes) should define the interaction between high-level and low-level modules. Details should depend on abstractions, not the other way around. |
| Application | Use dependency injection, inversion of control containers, and programming to interfaces to achieve loose coupling between modules. |
Dependency Inversion Principle states that “High-level modules should not depend on low-level modules. Both should depend on abstractions.” In simpler terms, your code shouldn’t be directly tied to specific implementations. Instead, it should rely on abstract interfaces or base classes that define the desired behavior, allowing for flexibility and adaptability.
class HighLevelModule {
private LowLevelModule lowLevelModule = new LowLevelModule();
public void doSomething() {
lowLevelModule.specificOperation();
}
}You can see that:
-
HighLevelModuleis tightly coupled toLowLevelModule, making it difficult to change or test independently. - Introducing a new
LowLevelModuleimplementation would require code changes inHighLevelModule.
To make the above functionality Dependency Inversion Principle compliant, we redesign our class as shown below:
interface Abstraction {
void operation();
}
class LowLevelModule implements Abstraction {
@Override
public void operation() {
// Specific implementation
}
}
class HighLevelModule {
private Abstraction abstraction;
public HighLevelModule(Abstraction abstraction) {
this.abstraction = abstraction;
}
public void doSomething() {
abstraction.operation();
}
}Now, you can see that:
-
HighLevelModuledepends on theAbstractioninterface, not the concreteLowLevelModule. - Concrete implementations can be injected through the constructor, allowing flexibility and testability.
- New implementations can be introduced without modifying
HighLevelModule.
A key consideration in the development of real-time applications is maintaining a loose coupling between High-level and Low-level modules. When a class possesses knowledge about the design and implementation of another class, it introduces the risk that any changes made to one class might disrupt the functionality of the other. Therefore, it is crucial to ensure loose coupling between high-level and low-level modules/classes. Achieving this involves making both modules dependent on abstractions rather than having direct knowledge or instance of each other.
Bibliography
Martin, Robert, and Sommerville, Ian. Value Pack: Software Engineering with Agile Software Development, Principles, Patterns and Practices. United Kingdom,Pearson Education, Limited, 2004.